Fast Data – Blogserie
Dies ist der dritte Teil der Blog Serie „Aufbau einer Fast Data Analytics Plattform“. Im ersten Teil „Bereitstellung einer Fast Data Analytics Plattform“ sind wir in die Rolle eines Taxiunternehmens geschlüpft, welches Taxi-Daten in Echtzeit sammelt und diese auf einem Realtime-Dashboard visualisieren möchte. Im zweiten Teil „Realtime Datenverarbeitung mit Spark Structured Streaming” wurde die Integration der Taxi-Daten in Echtzeit durch die Bereitstellung eines Streaming Hubs ermöglicht.
Datenverarbeitung
In diesem Blogbeitrag behandeln wir die Verarbeitung, Anreicherung und Persistenz der Taxi-Daten, durch die Bereitstellung eines Processing Hubs (vgl. Abbildung 1).
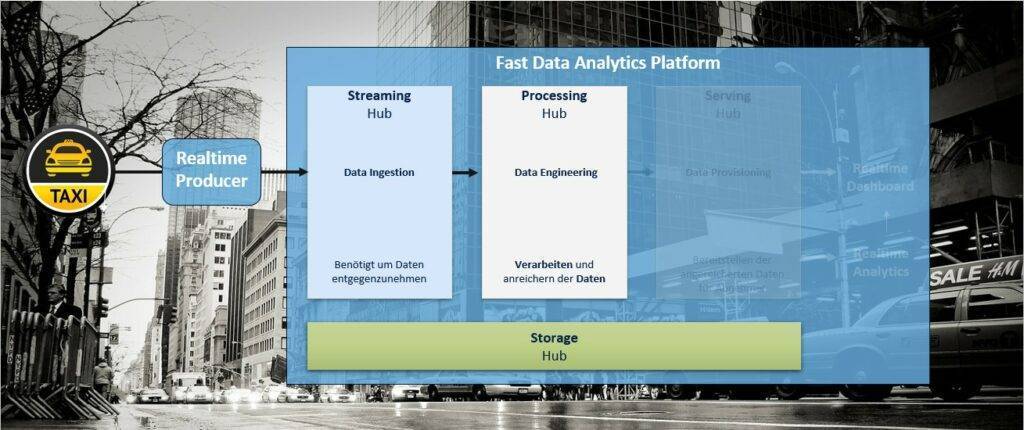
Aufbauend auf Realtime Datenintegration mit Apache Kafka müssen die in Kafka vorhandenen Daten weiterverarbeitet werden. Dabei gilt es zu beachten, dass durch die Verarbeitung eine möglichst geringe Verzögerung entsteht. Die Datenverarbeitung im Data Warehouse-Kontext wird typischerweise durch Batch-Verarbeitung realisiert. Hierbei werden in einem bestimmten Intervall (z.B.: 1x täglich) Verarbeitungsjobs gestartet, welche alle zu diesem Zeitpunkt vorhandenen Daten verarbeiten. Im Streaming Kontext ist diese Vorgehensweise suboptimal. Im Idealfall sollen die einkommenden Daten sofort weiterverarbeitet werden, um schnelle Entscheidungen und Reaktionen zu ermöglichen. Für die Verarbeitung der Daten wird eine Technologie benötigt, welche Echtzeitverarbeitung ermöglicht. Im Open Source-Bereich gibt es mehrere Frameworks, welche zum Einsatz kommen könnten:
- Flink
- Kafka Streams
- Spark Structured Streaming
Die Auswahl des passenden Verarbeitungs-Frameworks ist sehr stark abhängig von dem zu realisierenden Use Case.
Brauche ich Flink?
Flink ist eine „echte“ Echtzeitverarbeitung und bietet zusätzlich die Verarbeitung im Batch-Modus. Es zeichnet sich besonders durch den hohen Datendurchsatz und seine geringe Latenz aus. Ein möglicher Nachteil besteht darin, dass es sich um ein recht neues eigenständiges Framework handelt, für welches das technologische Wissen zunächst erworben werden muss, sofern nicht schon vorhanden.
Soll ausschließlich Kafka verwendet werden?
Kafka Streams ist vor allem dann sinnvoll, wenn ausschließlich Kafka genutzt werden soll. Diese Engine kommt typischerweise dann zum Einsatz, wenn die Architektur aus vielen einzelnen Microservices besteht, welche untereinander kommunizieren sollen.
Ist Spark schon im Einsatz?
Spark wird in vielen Unternehmen als einheitliche ETL-Engine für Batch-Verarbeitungen im Big Data Kontext eingesetzt. Der hohe Datendurchsatz bietet dank verteilter Rechenleistung eine schnelle Verarbeitung großer Datenmengen. Spark bietet mit Spark Structured Streaming eine Streaming-API für die Echtzeitdatenverarbeitung (Fast-ETL) an. Dies hat zum Vorteil, dass eine einheitliche Engine zum Einsatz kommen kann, mit welcher sowohl Batch als auch Streaming Daten verarbeitet werden können. Nachteilig ist, dass die Verarbeitung mit Spark Structured Streaming keine „echte“ Echtzeitverarbeitung ist, da die einzelnen Verarbeitungsschritte als Microbatches (i.d.R. < 500ms) abgearbeitet werden.
Flink, Kafka Streaming oder Spark Structured Streaming?
Für unseren Streaming Use Case entscheiden wir uns für den Einsatz von Spark Structured Streaming. Die Entscheidung führt darauf zurück, dass wir ein Framework einsetzen wollen, welches einheitlich für Streaming, Batch-Verarbeitungen und im Data Science Umfeld verwendet werden kann. Ein großer Vorteil von Spark ist, dass bestehende Batch-Jobs durch minimale Anpassungen in einen Streaming-Job umgewandelt werden können. Zusätzlich unterstützt das MTGen Streaming Modul bereits Spark sowohl für Batch als auch für Echtzeitdatenverarbeitung.
Bereitstellung Processing Hub
Für die Realisierung des Use Cases wird ein Processing Hub benötigt, auf dem Apache Spark zum Einsatz kommt. Die Aufgabe des Processing Hubs besteht darin, als zentrales Verarbeitungscluster (z.B.: Datenbereinigung, Datenanreicherung etc.) für Realtime-Daten zu dienen. Zusätzlich bietet der Processing Hub Data Scientists die Möglichkeit, Analysen auf großen Datenmengen zu realisieren.
Die Cloudera Data Plattform bietet vordefinierte Blaupausen für den Processing Hub an. Zur Bereitstellung muss lediglich der gewünschte Name vergeben werden und im Anschluss erfolgt die automatisierte Bereitstellung des Hubs. Im Zuge der Bereitstellung wird ein Cluster mit 4 Knoten initialisiert, welches automatisch an den Basis-Cluster der Plattform und somit an den Data Lake angeschlossen ist. Diese Bereitstellung erfolgt in unter einer Stunde und enthält unter anderem folgende Services:
- Apache Spark (Verarbeitung)
- Apache Hive (Persistenz)
- Hue (SQL Editor)
- Apache Zeppelin (Data Analytics)
- Apache Oozie (Jobsteuerung)
Bevor die Daten mit Hilfe des Processing Hubs verarbeitet werden können, muss die Möglichkeit geschaffen werden, die Daten zu persistieren und für nachfolgende Anwendungen (z.B.: Visualisierungs-Tools) bereitzustellen.
Bereitstellung Serving Hub
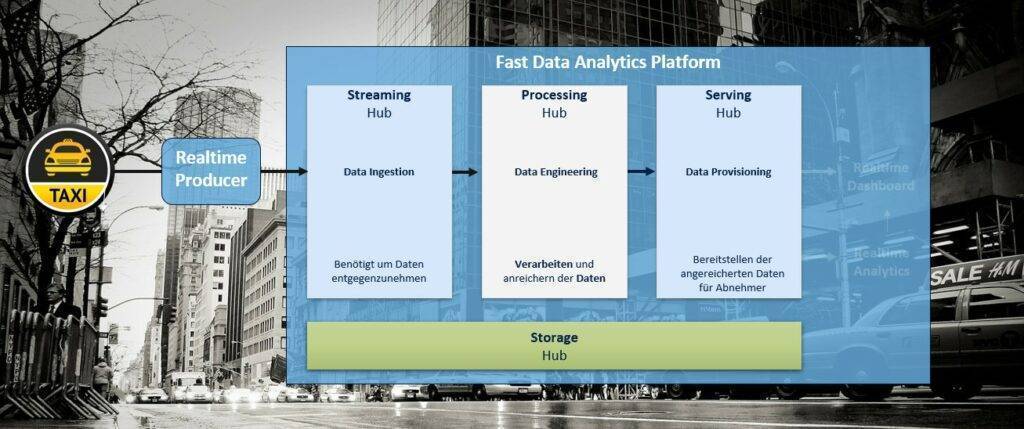
Die Persistenz der Daten ist notwendig, um Data Scientisten die Möglichkeit zu bieten analytisch mit den vorhandenen Daten zu arbeiten und Vorhersagemodelle zu entwickeln, welche im späteren Verlauf auch während der Echtzeitverarbeitung berücksichtigt werden können.
Die Daten können in einer oder mehreren Formen abgespeichert werden. Typischerweise kommen hier Dienste wie Hive, HBase, Kudu, Hudi oder auch Dateien im HDFS zum Einsatz. Für unseren Streaming Use Case haben wir uns für die Speicherung der Daten in Kudu entschieden. Apache Kudu ist ein Speicherformat, welches speziell für schnelle analytische Abfragen auf sich schnell ändernden Daten entwickelt wurde.
Die Bereitstellung des Serving Hubs verläuft analog zu der Bereitstellung des Processing Hubs. Auch hier bietet die Cloudera Data Plattform eine vordefinierte Blaupause. Im Zuge der Bereitstellung wird ein Cluster initialisiert, welches automatisch an den Basis-Cluster der Plattform und somit an den Data Lake angeschlossen ist. Diese Bereitstellung erfolgt in unter einer Stunde und enthält unter anderem folgende Services:
- Apache Kudu (Persistenz)
- Apache Impala (Abfrage Engine)
- Apache Hue (SQL Editor)
- Apache Spark (Verarbeitung)
Der in Realtime Datenintegration mit Apache Kafka (Fast Data Teil 2) bereitgestellte Streaming Hub dient als Datendrehscheibe für Echtzeitdaten und übernimmt somit auch die Rolle als Serving Hub.
Nachfolgend ist die gesamte Architektur inklusive der verwendeten Dienste dargestellt.
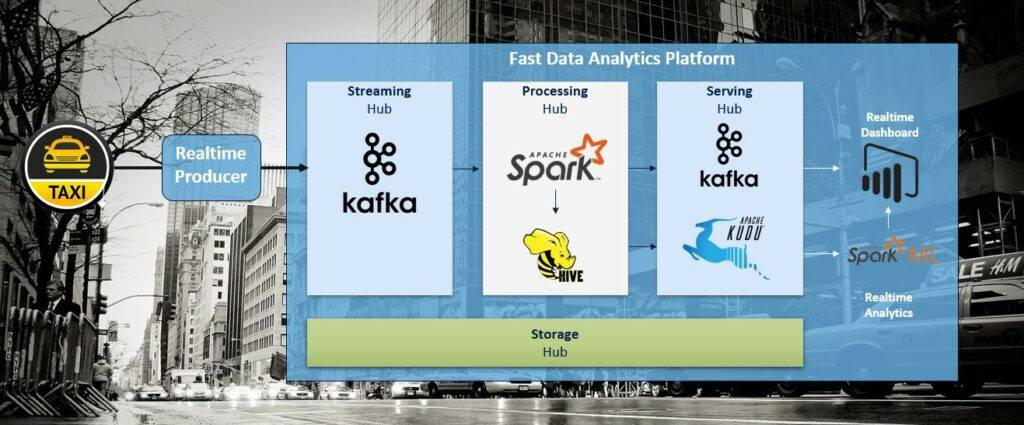
MTGen Streaming Processor
Wie bereits in Realtime Datenintegration mit Apache Kafka beschrieben ist die MT ein großer Befürworter der Automatisierung von Ladestrecken mit Hilfe von Metadaten-getriebenen Ansätzen. Daher wurde der Metadaten-getriebenen Generator MTGen für den Streaming Use Case um ein Streaming Modul erweitert. Dieses Modul enthält einen generischen Producer sowie eine generische Streaming Anwendung als auch einen generischen Consumer.
Die generische Streaming-Anwendung ermöglicht die Instanziierung von Verarbeitungsjobs auf Basis von Konfigurationsdateien. Durch den generischen Ansatz kann die Verarbeitungslogik (z.B. Anreicherung mit Stammdaten, Joinen von Streams, Aggregationen etc.) von „außen“ in Form von SQL-Anweisungen zugesteuert werden. Zusätzlich können bestehende Spark ML Modelle für Vorhersagen integriert werden. Als Datenquelle wird Kafka verwendet. Weiterhin unterstützt die Anwendung eine Reihe von Datensenken. Zu den unterstützten Datensenken zählen unter anderem:
- Apache HBase
- HDFS
- Apache Hive
- Apache Kudu
- Apache Hudi
- Apache Kafka
- InfluxDB
Die Streaming-Anwendung wird mit einer Konfigurationsdatei instanziiert, welche unter anderem folgende Informationen enthält:
- In welchem Kafka Topic befinden sich die Daten?
- Welche Datensenke soll verwendet werden?
- Welche Transformationslogik soll angewendet werden?
- Welches Machine Learning Modell soll angewendet werden?
Starten der Realtime Datenverarbeitung
Um die Datenverarbeitung in Echtzeit zu starten, muss der MTGen Streaming Processor lediglich konfiguriert werden.
Der MTGen Streaming Processor wird auf dem Processing Hub bereitgestellt und gestartet. Nach dem Starten wird eine Spark Structured Streaming Applikation innerhalb des Hubs gestartet, welche auf verschiedenen Knoten verteilt läuft und dort die einkommenden Daten in Echtzeit verarbeitet. Innerhalb der Verarbeitung werden die Daten mit Stammdaten angereichert, welche zusätzliche Informationen zu den einzelnen Taxi-Zonen enthalten. Diese Daten wurden zuvor in Form von relationalen Tabellen in Hive bereitgestellt. Als Datensenken dienen zum einen Kudu (für spätere Data Science-Analysen) als auch Kafka (für die Visualisierung der Daten in Echtzeit). Die verarbeiteten Daten in der Kafka-Senke dienen als Input für das Realtime-Dashboard in Power BI.

In diesem Teil der Blogserie „Aufbau einer Fast Data Analytics Plattform“ wurde die Verarbeitung, Anreicherung, Speicherung und Bereitstellung (Visualisierung) der Echtzeitdaten behandelt (vgl. Abbildung 5).
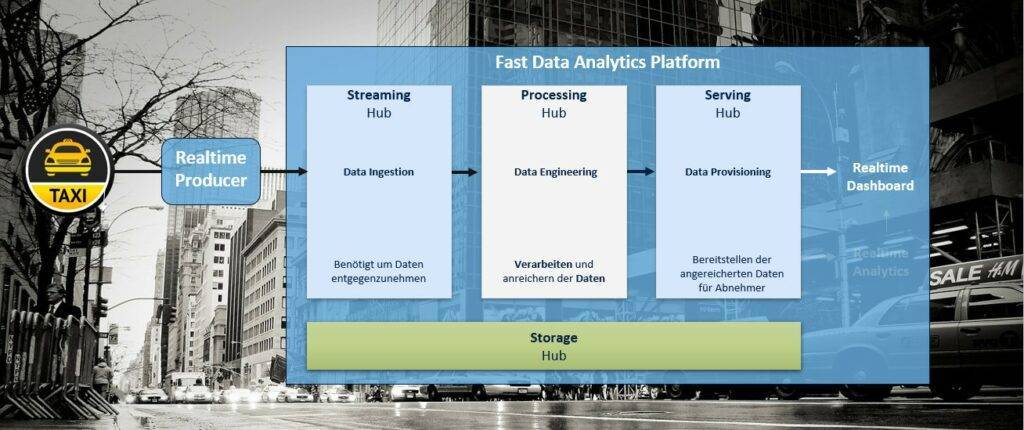
Im nächsten Teil dieser Blogserie skizzieren wir „Realtime Prediction mit Machine Learning Algorithmen“.