Fast Data – Blogserie
„Wäre es nicht großartig, wenn wir…“ – dieser Satz ist vermutlich jedem schon einmal im Berufsleben in dieser oder einer abgewandelten Form begegnet. Am Anfang steht immer eine Idee, aus welcher sich interessante Use Cases ableiten lassen. Viele unserer Kunden kommen mit einer solchen Idee auf uns zu und fragen nach Unterstützung für ihre Ideen oder die Ideen entstehen im Rahmen gemeinsamer Projekte.
In den letzten Jahren begegnet man vermehrt Schlagwörtern wie Big Data, Fast Data, Realtime, Data Science, Machine Learning, Künstliche Intelligenz oder auch Realtime-Dashboarding. Viele dieser Begriffe nutzen oder bauen auf Big Data-Technologien auf. In dieser Blogbeitrags-Serie skizzieren wir unser generelles Vorgehen für das Bereitstellen einer Fast Data Analytics-Plattform und einer End-To-End Verarbeitung von Echtzeitdaten am Beispiel eines (MT AG) internen Use Cases.
Am Anfang steht die Idee
Die Fachabteilungen eines Unternehmens sind häufig die treibenden Kräfte, wenn es um Ideenentwicklung für neue Use Cases oder die Erfüllung von unternehmenskritischen Anforderungen geht – sei es eine Verbesserung oder Vereinfachung der täglichen Arbeit oder eine neue Form der Bereitstellung, Analyse oder Visualisierung von aktuellen Daten (vgl. Abbildung 1).
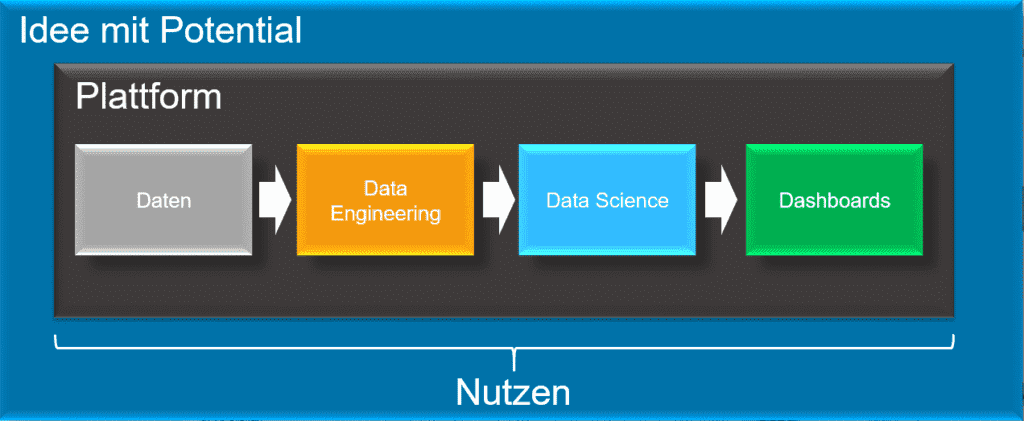
Für unser Beispiel schlüpfen wir in die Rolle eines Taxiunternehmens. Unsere Fachabteilung hat die Idee entwickelt, aktuelle Taxi-Daten auf einem Realtime-Dashboard anzuzeigen, um aktuelle Informationen zum Geschehen auf der Straße zu erhalten. Zusätzlich sollen Vorhersagen (Realtime-Predictions) für den Bedarf an Taxis in der nächsten Stunde getroffen werden. Die Idee hat sie in Form einer Skizze festgehalten.
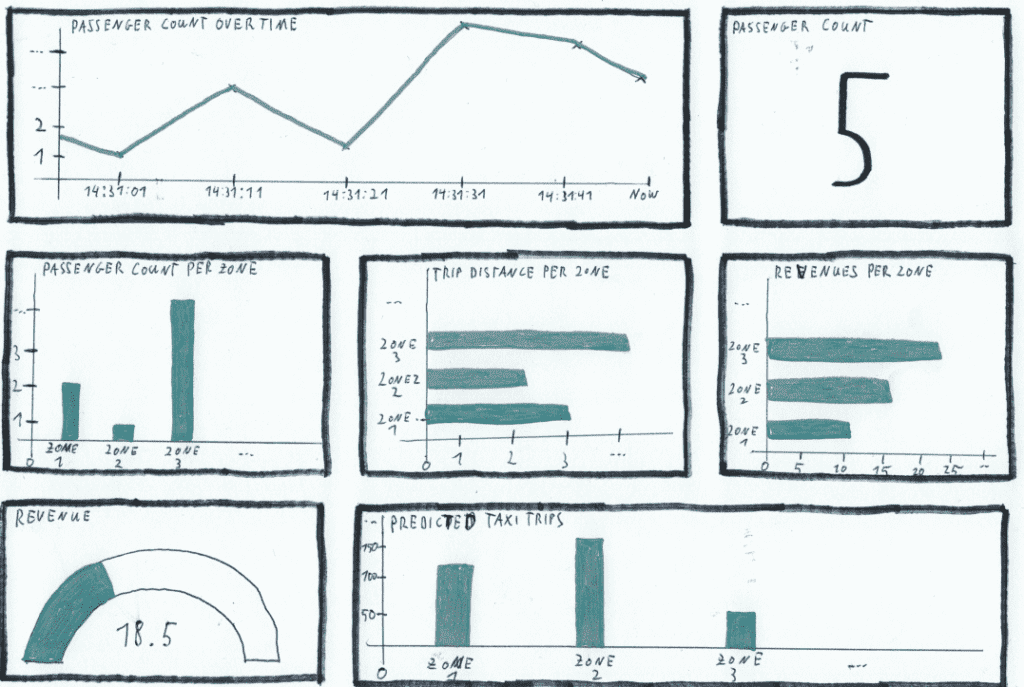
Wie auf der Abbildung 2 zu erkennen ist, soll die Anzahl der Passagiere der letzten 30 Sekunden angezeigt werden. Zusätzlich sollen Kennzahlen wie die aktuelle Passagieranzahl, die Passagieranzahl pro Zone im Stadtgebiet oder die zurückgelegte Fahrtstrecke visualisiert werden. Neben diesen Informationen soll das Dashboard auch eine Vorhersage für die Anzahl der Taxifahrten innerhalb der nächsten Stunde enthalten.
Aus der ursprünglichen Skizze ist im Rahmen der Umsetzung ein Realtime-Dashboard mit PowerBI entstanden. Die implementierte Datenverarbeitungsstrecke basiert hierbei auf einem metadatengetriebenen Ansatz (MTGen-Streaming).

In dieser Blogbeitrags-Serie erklären wir, wie aus einer Idee zum Thema Fast Data-Analytics ein Werkzeug entsteht, welches einen deutlichen Mehrwert für ein Unternehmen generieren kann, da auf Basis von aktuellen Daten (unter einer Sekunde) schnell auf geschäftsrelevante Ereignisse reagiert werden kann, was mit klassischen Batch-Architekturen nicht möglich wäre. Hierbei werden alle Aspekte von der initialen Bereitstellung der Plattform bis hin zur Visualisierung der Realtime-Daten behandelt.
Die nächsten Abschnitte beschäftigen wir uns mit der Auswahl der passenden Plattform-Technologie sowie der initialen Bereitstellung der Fast Data Analytics-Plattform.
Anforderungen an die Plattform
Mit der Idee und der ersten groben Definition des Use Cases geht unsere Fachabteilung nun auf die IT-Abteilung unseres Unternehmens zu. Bevor sich unsere IT-Abteilung mit der Umsetzung des Use Cases beschäftigen kann, wird im ersten Schritt zunächst eine passende Plattform benötigt.

Für die Auswahl der geeigneten Plattform und Technologien ist es sinnvoll, zunächst grobe Anforderungen an die Plattform zu definieren. Der vorgegebenen Use Case impliziert schon einige davon, wie beispielsweise:
- Die Daten müssen in Realtime integriert und verarbeitet werden
- Das Dashboard soll die Daten in Realtime darstellen
- Die Daten müssen gespeichert werden, um später aus ihnen lernen zu können
- Die Echtzeit-Daten müssen mit Stammdaten angereichert werden
Diese Anforderungen helfen uns bei der Beantwortung folgender technischer Fragen:
- Soll die Plattform in der Cloud oder On-Premise entstehen?
- Infrastructure-as-a-service[1] (IaaS), Plattform-as-a-Service[2] (PaaS) oder Software-as-a-Service[3] (SaaS)?
- Welche Datenmengen müssen integriert werden?
- Welches Datenwachstum ist zu erwarten?
- Wie stark und wie schnell muss die Plattform skalieren können?
- Wer soll alles Zugriff auf die Plattform bekommen?
- Wie flexibel muss die Plattform sein, um beispielweise weitere Use Cases leicht umsetzen zu können?
Cloud oder On-Premise?
Mit Hilfe der Anforderungen kann nun eine geeignete Big Data-Plattform ausgewählt werden. Bei unserem Anwendungsfall haben wir uns für die Bereitstellung in der Microsoft Cloud Azure entschieden. Einer der Vorteile der Cloud besteht darin, dass benötigte Ressourcen schnell und einfach angemietet werden können und keine Zeit verstreicht, bis entsprechende Hardware bereitsteht. Dies ermöglicht bei kurzfristigen Spitzenlasten die Plattform hoch- und herunterskalieren zu können, ohne dass ständig das Maximum an Hardware im Rechenzentrum vorgehalten werden muss. Ein weiterer Vorteil besteht darin, dass Kosten signifikant reduziert werden können, da im Vorfeld keine teure Hardware eingekauft werden muss.
Bei der Auswahl der Plattform stellt man jedoch schnell fest, dass es vor allem in der Cloud eine sehr große Anzahl an Produkten gibt, welche potenziell zum Einsatz kommen können. Neben den proprietären Angeboten von Anbietern wie Microsoft, Amazon oder Google gibt es eine Reihe weiterer Angebote von Drittanbietern.
Auswahl der passenden Plattform
In unserem Fall haben wir die Hadoop-Distribution „Cloudera Data Plattform“ (CDP) gewählt, da diese sowohl in Azure, AWS aber auch On-Premise genutzt werden kann (PaaS). Diese Distribution enthält darüber hinaus eine große Auswahl an bewährten BigData-Technologien wie beispielsweise Hive, HBase, Spark, Kafka und viele mehr, welche über zentrale Benutzeroberflächen administriert werden können. Des Weiteren unterstützt CDP grundlegende zentrale Sicherheitskonzepte (z.B.: Kerberos, Integration des Unternehmens-AD und Rechteverwaltung) sowie Governance-Konzepte (z.B.: Data Lineage) von Hause aus (Cloudera SDX) und kann somit direkt im Unternehmensumfeld produktiv eingesetzt werden.
Initiale Bereitstellung der Plattform
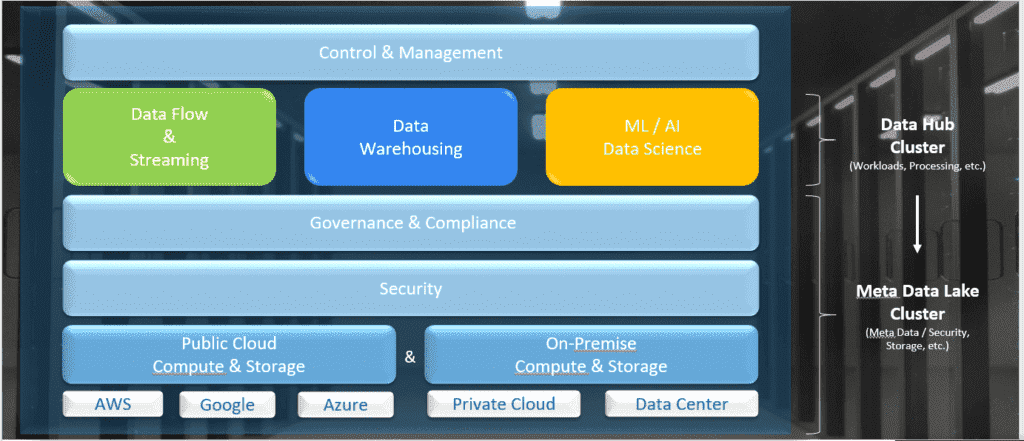
Bei der initialen Bereitstellung der Fast Data Analytics Plattform wird automatisiert ein Metadaten-Cluster in Azure erstellt. Dieses Cluster, auch Basis-Cluster genannt, enthält die Verbindungen zum CloudStorage (Data Lake) aber auch Sicherheitsrichtlinien und Bestimmungen für alle verwendeten Services innerhalb der Plattform (vgl. Abbildung 3). Weitere Cluster (Data-Hubs) können nachträglich mit dem Basis-Cluster verknüpft werden und erben so alle dort hinterlegten Informationen. Zusätzlich dient es als logische Klammer für die Fast Data Analytics-Plattform.
Bevor die Fast Data Analytics-Plattform in CDP bereitgestellt werden kann, müssen zunächst einige wenige Schritte erfolgen:
- Hinterlegen unserer Azure-Abonnement Informationen in CDP
- Erstellen eines Cloud Speichers in Azure
Nachdem diese Schritte erfolgt sind, kann in CDP mit wenigen Klicks die Fast Data Analytics-Plattform konfiguriert werden. Anschließend erfolgt die automatisierte Bereitstellung aller benötigten Ressourcen in Azure. Nach ca. einer Stunde steht uns die Plattform zur Verfügung (vgl. Abbildung 4) und wir sind nun in der Lage direkt mit der Umsetzung des Use Cases zu beginnen, ohne durch langwierige Hardware Anschaffungs- und Bereitstellungsprozesse ausgebremst zu werden.
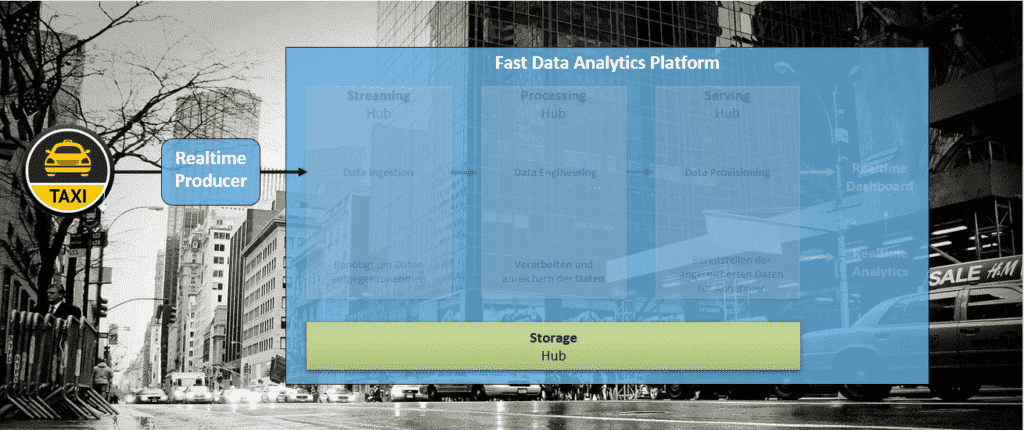
In diesem Teil der Blogbeitrag-Serie „Aufbau einer Fast Data Analytics-Plattform“ wurde das Vorgehen bei der Auswahl einer passenden Plattform-Technologie anhand eines internen Use Cases skizziert. Im nächsten Teil beschäftigen wir uns mit der Bearbeitung des Use Cases und der Integration der Daten in Echtzeit.
[1] Ein Provider bietet Kunden Zugang zu Speicher, Netzwerkkomponenten, Servern und weiteren IT-Ressourcen in der Cloud. Die Abrechnung erfolgt auf Basis der Nutzung.
[2] Ein Service-Provider bietet den Nutzern Zugang zu einer Cloud-basierten Umgebung. Der Provider stellt die zugrunde liegende Infrastruktur zur Verfügung.
[3] Ein Service-Provider stellt Software und Anwendungen über das Internet bereit. Die Nutzer abonnieren diese und greifen per Web oder über APIs des Anbieters darauf zu.
Fast Data – Blogserie Teil 2:
Realtime Datenintegration mit Apache Kafka »
Fast Data – Blogserie Teil 3:
Realtime Datenverarbeitung mit Spark Structured Streaming »
Fast Data – Blogserie Teil 4:
Realtime Prediction mit Machine Learning Algorithmen »