Fast Data – Blogserie
Dies ist der zweite Teil der Blog Serie zum Thema „Aufbau einer Fast Data Analytics Plattform“. Im ersten Teil „Bereitstellung einer Fast Data Analytics Plattform“ sind wir in die Rolle eines Taxiunternehmens geschlüpft, welches Taxi-Daten in Echtzeit sammelt und diese auf einem Realtime-Dashboard visualisieren möchte. Zusätzlich haben wir in diesem Blogbeitrag gezeigt, wie schnell und einfach es ist eine initiale Plattform in der Cloud bereit zu stellen.
Datenintegration
In diesem Beitrag beschäftigen wir uns mit der Integration von Realtime-Daten durch die Bereitstellung eines Streaming Hubs (vgl. Abbildung 1).
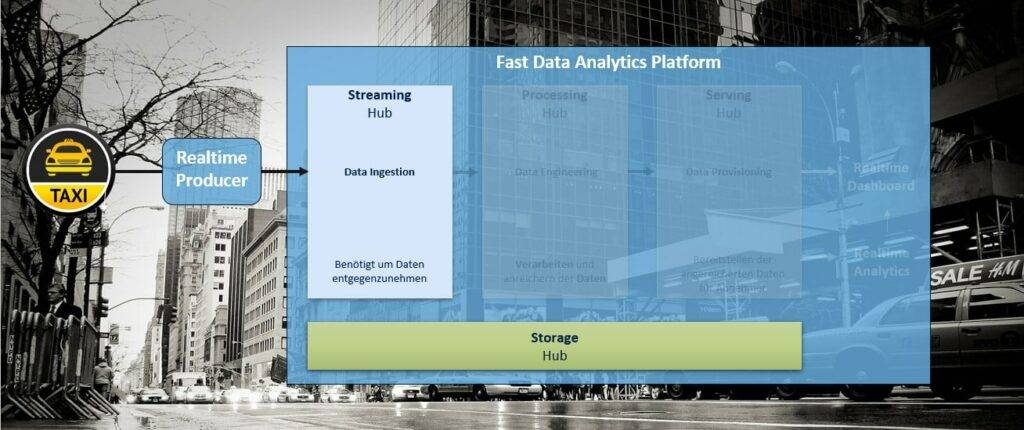
Zunächst müssen die Daten in irgendeiner Form entgegengenommen werden. Hierbei unterscheidet man typischerweise zwischen Pull-(Daten werden regelmäßig abgeholt) und Push-(Daten werden an die Plattform gesendet) Mechanismen. Im Falle von Echtzeitdatenverarbeitung nutzt man den Push-Mechanismus, da die Daten so schnell wie möglich weitergeleitet werden sollen.
Realtime – Aber wie?
Die IT-Abteilung unseres fiktiven Taxiunternehmens steht vor der Frage, welche Technologie für einen Streaming Use Case zum Einsatz kommen soll.
In den letzten Jahren hat sich Apache Kafka als defacto Standard für Realtime-Anwendungen durchgesetzt. Apache Kafka ist ein verteiltes, skalierbares und fehlertolerantes System, welches sich besonders gut für ereignisbasierte-Anwendungen mit großen Datenmengen eignet und als Open Source Software verfügbar ist. In seiner einfachsten Form besteht ein Kafka-Cluster aus einer Anzahl von Servern (Brokern), welches Schlüssel-Wert-Paare (Records) zusammen mit einem Zeitstempel in einer Art Log (Topic) speichert. Topics wiederum bestehen aus einer oder mehreren Partitionen, um Skalierung durch Parallelisierung zu ermöglichen. Anwendungen, die Daten an Kafka senden, werden als Producer bezeichnet. Anwendungen, die Daten von Kafka lesen als Consumer.
Bereitstellung Streaming Hub
Für die Realisierung des Use Cases wird ein Streaming Hub benötigt, der auf Apache Kafka aufbaut. Die Aufgabe des Streaming Hubs besteht ausschließlich darin, als Datendrehscheibe für Realtime-Daten zu dienen. Verschiedene Anwendungen können ihre Daten an diese Drehscheibe senden, wo diese für den weiteren Verarbeitungsprozess vorgehalten werden.
Die Cloudera Data Plattform bietet vordefinierte Blaupausen für den Streaming Hub an. Zur Bereitstellung muss lediglich der gewünschte Name vergeben werden und im Anschluss erfolgt die automatisierte Bereitstellung des Hubs. Im Zuge der Bereitstellung wird ein Cluster initialisiert, welches automatisch an den Basis-Cluster der Plattform und somit an den Data Lake angeschlossen ist. Diese Bereitstellung erfolgt in unter einer Stunde und enthält unter anderem folgende Services:
- Apache Kafka
- Streams Messaging Manager (Monitoring für Kafka)
- Schema Registry (Zentrale Registry für Definitionen der Record-Strukturen)
Im Anschluss können Daten an den Streaming Hub gesendet werden.
Datenquellen
Da wir, als MT keine eigene Taxi-Flotte besitzen, wird auf bestehende Open Data Datensätze zurückgegriffen und die Generierung der Daten simuliert. Als Datenquelle dienen die Yellow-Trip-Taxi Daten der Stadt New York aus den Jahren 2018 und 2019. Insgesamt besteht der Datensatz aus ca. 187 Millionen Datensätzen. Die Daten liegen in monatlichen Scheiben als CSV-Datei vor. Um den Realtime-Aspekt zu simulieren, werden die Dateien nacheinander Zeile für Zeile eingelesen und jede Zeile als einzelner Datensatz an den Streaming Hub geschickt. Hierbei wurden pro Sekunde 100 Datensätze gesendet.
MTGen Streaming Producer
Wir sind ein großer Befürworter der Automatisierung von Ladestrecken mit Hilfe von Metadaten-getriebenen Ansätzen. Deshalb haben wir in verschiedenen Projekteinsätzen bei unterschiedlichen Kunden ein Metadaten-getriebenen Generator, den MTGen für standardisierte Beladungsstrecken entwickelt. Zunächst wurde dieser im traditionellen Data Warehouse-Kontext genutzt, um neue Datenquellen an das Data Warehouse anzubinden. In mehreren Kunden-Projekten wurde dieser Generator anschließend Big-Data tauglich gemacht, um relationale Datenquellen mit Hilfe von Hadoop-Technologien an einen Data Lake anzubinden. Ein großer Vorteil dieses Ansatzes ist, dass neue Datenquellen innerhalb kürzester Zeit angebunden werden können, da die Metadaten (Tabellenname, Datenfelder, Datentypen etc.) von außen zugesteuert werden.
Für den Streaming Use Case wurde der Generator, um ein Streaming Modul erweitert. Dieses Modul enthält einen generischen Producer sowie eine generische Streaming Anwendung als auch einen generischen Consumer (mehr dazu in nachfolgenden Beiträgen).
Der Producer wird mit einer Konfigurationsdatei instanziiert, die unter anderem folgende Informationen enthält:
- Wo befindet sich die Quelldatei?
- In welchem Format sollen die Daten gesendet werden (JSON, AVRO)
- Wo befindet sich das Kafka-Cluster?
- In welchem Zeitintervall sollen die Daten gesendet werden (Simulieren von Lasttests)?
- Authentifizierungsinformationen
Starten der Realtime Datenintegration
Um die Datenintegration in Echtzeit zu starten, muss der MTGen Streaming Producer lediglich konfiguriert werden. Die Daten sollen im Avro-Format übertragen werden, daher wird zunächst das Avro Schema definiert.
Apache Avro ist ein Serialisierungs-Framework, welches als Teil von Apache Hadoop entwickelt wurde. Datentypen sowie das Schema der Datensätze werden in einer Schema-Datei als JSON definiert. Die Daten werden auf Basis des Schemas in ein kompaktes Binärformat serialisiert. Durch die Umwandlung in ein kompaktes Binärformat lässt sich die zu übertragende Datenmenge deutlich reduzieren, was eine Steigerung der Performanz zur Folge hat. Zusätzlich wird durch das Schema garantiert, dass die Struktur der Datensätze immer gleich ist.
Anschließend werden die Referenz auf die Quelldatei sowie die benötigten Informationen zum Kafka-Cluster hinterlegt.
Der MTGen Streaming Producer wird auf einer gesonderten, virtuellen Linux Maschine in Azure bereitgestellt und gestartet, um die Simulation des Sendens von Datensätzen von außerhalb der Fast Data Analytics Plattform zu realisieren.
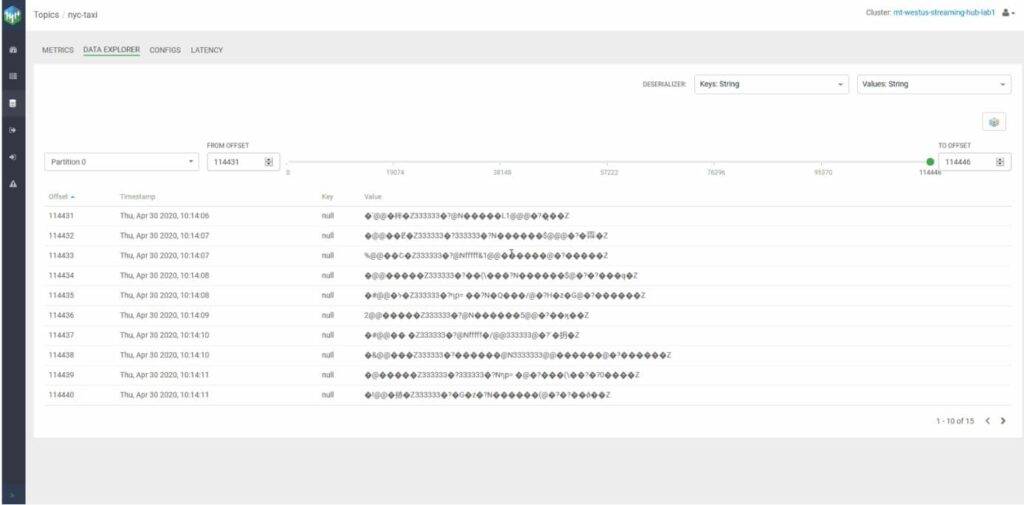
Abbildung 2: Realtime Monitoring Apache KafkaÜber das Monitoring-Tool Streams Messaging Manager können die eingehenden Daten in Echtzeit beobachtet werden. Zu beachten ist, dass der in der Oberfläche angezeigte Payload binär dargestellt wird.
In diesem Teil der Blog Serie „Aufbau einer Fast Data Analytics Plattform“ wurde mit der Bearbeitung des Streaming Use Cases begonnen und die Integration von Realtime-Daten durch die Bereitstellung eines Streaming Hubs in kürzester Zeit (1 Stunde) ermöglicht. Im nächsten Teil beschäftigen wir uns mit der Verarbeitung, Anreicherung und Speicherung der Realtime-Daten.