Um IT-Infrastrukturen oder einzelne Arbeitsumgebungen umzusetzen, nutzen moderne Unternehmen die Cloud. Mittels moderner Infrastructure-as-Code-Technologien können sie ihre Bereitstellungsmethoden automatisieren. Infrastructe as Code (IaC) ermöglicht es, dass sich vollständige Systemumgebungen für Anwendungen deklarativ definieren lassen. Fortan unterliegt nicht nur die ausgerollte Anwendung, sondern die gesamte zugrunde liegende Infrastruktur einer Versionierung sowie einer automatisierten und reproduzierbaren Bereitstellung.
Das amerikanische Unternehmen HashiCorp. bietet mit Terraform eine Software, mit der die Cloud-Umgebung flexibel nutzbar ist. Wie, zeigen wir in unserem Praxisbeispiel.
Was ist Terraform und wie unterstützt es Anwender bei der Konzeption von Infrastructure as Code?
Terraform ist ein Open-Source-Tool, welches die einfache und schnelle Umsetzung von Infrastructure as Code ermöglicht. Der Entwickler HashiCorp ist bereits bekannt durch Tools wie Vault oder Vagrant. Terraform unterstützt über sogenannte Provider alle bekannten Cloud-Anbieter. Die Terraform Registry verfügt über mehr als 500 verschiedene Provider, die neben Cloud-Anbietern auch die Konfiguration verschiedener Software-Komponenten unterstützen.
Die Infrastruktur wird in Terraform-Dateien mit der Endung tf festgehalten. Der Code wird in der hauseigenen Sprache HCL (HashiCorp Language) verfasst, die auch für Terraform-Neulinge leicht verständlich ist und somit einen schnellen Einstieg ermöglicht. Der entstandene Code kann wie jeder herkömmliche Code mit einem SCM-Tool, wie etwa Git, versioniert werden. Zudem besteht die Möglichkeit, den Code zu modularisieren, sodass er in weiteren Projekten wiederverwendet werden kann. Terraform arbeitet deklarativ: Die Entwickler*innen beschreiben nur die Zielsituation, die auszuführenden Schritte berechnet das Programm automatisch. Die Abhängigkeiten zwischen verschiedenen Ressourcen werden dabei durch Terraform erkannt und in einem Dependency graph festgehalten.
Anhand einer exemplarischen Anwendung, die mit Microsoft-Infrastruktur in der Azure Cloud betrieben werden soll, zeigen wir euch im Detail, wie Terraform die Arbeit in Cloud-Umgebungen erleichtert:
Terraform in der Praxis – ein Beispiel in Azure
Unsere Anwendung benötigt dabei noch eine Datenbank, um Daten zu persistieren. Da wir vorzugsweise cloudnative arbeiten wollen, verwenden wir das Produkt Azure Database for PostgreSQL Server.
Das Basis-Setup
Zunächst referenzieren und konfigurieren wir den Provider von Azure. Dieser kommuniziert intern mit der API von Azure, um die Ressourcen aus dem Terraform-Code zu verwalten. Sensible Anmeldeinformationen werden aus den Umgebungsvariablen geladen, damit diese nicht im Code hinterlegt werden müssen. Dieser Vorgang kann individuell für den jeweiligen Anwendungsfall angepasst werden.
Der Provider wird durch den folgenden ersten Block referenziert. Dabei werden der Name und eine feste Version angegeben, sodass Aktualisierungen keine unerwarteten Änderungen verursachen. Der zweite Block ist providerspezifisch und enthält dessen Konfiguration. In unserem Beispiel müssen wir keine der Funktionen anpassen, weshalb wir den Block features leer lassen. In unserer Anwendung ist es nicht erforderlich, die Provider zu registrieren, weshalb wir dieses Verhalten deaktivieren.
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "2.42.0"
}
}
}
provider "azurerm" {
features { }
skip_provider_registration = true
}
(Siehe providers.tf)
Die Interaktion mit Terraform erfolgt über die Kommandozeile. Die letztendliche Ausführung kann somit unter anderem auf dem Computer des*der Entwicklers*in als auch in einer CI/CD-Pipeline erfolgen. Um den Code auszuführen, muss zunächst eine Initialisierung durchgeführt werden – vergleichbar mit dem Herunterladen der Abhängigkeiten wie zum Beispiel bei .NET oder Node.js. Angestoßen wird dieser Prozess über den Befehl [terraform init]. Bei der Ausführung werden alle Terraform-Dateien im aktuellen Ordner eingelesen.
Die erste Ressource
Nun können wir auch schon anfangen, die gewünschte Infrastruktur zu beschreiben. Bei Azure sind Ressourcen den sogenannten Ressourcengruppen zugeordnet, die separat verwaltet werden können. Ein entsprechender Ressourcenblock wird in der Datei [main.tf] erstellt. Die nutzbaren Ressourcentypen sind in der Dokumentation des Providers aufgelistet. Die Datei main.tf ist von Terraform selbst nicht erforderlich. Sie spielt hierbei nur auf zentrale und gemeinsam genutzte Komponenten an. Theoretisch kann der gesamte Code in einer einzigen Datei liegen. Wie bei regulärem Code ist es empfehlenswert, aus Gründen der Lesbarkeit und Übersichtlichkeit, den Code sinnvoll aufzuteilen.
resource "azurerm_resource_group" "main" {
name = "basic-app-project"
location = "West Europe"
}
(Siehe main.tf)
Die PostgreSQL-Datenbank
Weitergehend benötigen wir die gerade schon angesprochene Datenbank. Die Struktur der Ressourcen orientiert sich meist an der API des Cloud-Anbieters. Zunächst wird also ein PostgreSQL-Server benötigt. Ab diesem Punkt ist es sinnvoll, die Arbeit in einer neuen Datei – etwa [database.tf] – fortzusetzen.
resource "azurerm_postgresql_server" "app_database_server" {
name = "app-database-server-hg348f"
resource_group_name = azurerm_resource_group.main.name
location = azurerm_resource_group.main.location
administrator_login = "admin"
administrator_login_password = "123456"
sku_name = "B_Gen5_2" # Basic + Gen 5 + 2 vCores
version = "11"
}
(Siehe database.tf)
Das kryptisch anmutende Suffix ist notwendig, da bei Azure Datenbanknamen global einzigartig sein müssen. Bei der Angabe der Ressourcengruppe und des Standorts beziehen wir uns nun auf die gerade deklarierte Ressourcengruppe. Anhand solcher Referenzen kann Terraform den bereits erwähnten Abhängigkeitsbaum aufbauen. Die verwendeten Parameter und die dafür zulässigen Werte sind in der Dokumentation zu finden. In einem produktiv genutzten System sollten die Zugangsdaten aus einer Variablen bezogen werden, deren Inhalt nicht Teil des Codes ist.
Zusätzlich benötigen wir noch eine Firewall-Regel für die Datenbank, die unserer Anwendung den Zugriff gestattet. Wir nutzen für unsere Anwendung den Azure App-Service. Um die Azure-Dienste zu erlauben, wird die IP-Adresse [0.0.0.0] von Azure als Platzhalter genutzt. Wir beziehen uns wieder auf die zuvor deklarierte Ressourcengruppe und den Datenbank-Server.
resource "azurerm_postgresql_firewall_rule" "azure_services_rule" {
name = "azure-services"
resource_group_name = azurerm_resource_group.main.name
server_name = azurerm_postgresql_server.main.name
start_ip_address = "0.0.0.0"
end_ip_address = "0.0.0.0"
}
(Siehe database.tf)
Nun folgt die eigentliche Datenbank in PostgreSQL. Die beiden Parameter [charset] und [collation] sind erforderlich.
resource "azurerm_postgresql_database" "app_database" {
name = "app-data"
resource_group_name = azurerm_resource_group.main.name
server_name = azurerm_postgresql_server.main.name
charset = "UTF8"
collation = "English_United States.1252"
}
(Siehe database.tf)
Der App-Service für die Anwendung
Nachdem wir die Datenbank-Infrastruktur erfolgreich deklariert haben, können wir den App-Service beschreiben, in welchem die Anwendung später ausgeführt wird. Ein App-Service in Azure erfordert das vorherige Erstellen eines App-Service-Plans, welchen Terraform ebenfalls abgedeckt.
resource "azurerm_app_service_plan" "main_app_service_plan" {
name = "main-app-service-plan"
resource_group_name = azurerm_resource_group.main.name
location = azurerm_resource_group.main.location
sku {
tier = "Basic"
size = "B1"
}
}
(Siehe app.tf)
Bei der Anwendung handelt es sich um eine .NET-5-Anwendung. Die Parameter setzen wir einfach anhand der Dokumentation. Um eine Verbindung aufzubauen, erhält die Anwendung noch die Zugangsdaten der Datenbank. Dafür werden einfach die entsprechenden Werte aus den vorherigen Ressourcen übernommen und der Anwendung als Umgebungsvariablen zur Verfügung gestellt. Im Fall des Datenbanknutzers müssen wir die Werte aneinanderhängen, um die Konvention von PostgreSQL zu erfüllen. Bei den anderen Werten referenzieren wir wie vorher die Werte des App-Service-Plans und der Ressourcengruppe.
resource "azurerm_app_service" "main_app_service" {
name = "app-34uhqr"
resource_group_name = azurerm_resource_group.main.name
location = azurerm_resource_group.main.location
app_service_plan_id = azurerm_app_service_plan.main_app_service_plan.id
app_settings = {
"DB_HOSTNAME" = azurerm_postgresql_server.app_database_server.fqdn
"DB_DATABASE" = azurerm_postgresql_database.app_database.name
"DB_USERNAME" = "${azurerm_postgresql_server.app_database_server.administrator_login}@${azurerm_postgresql_server.app_database_server.fqdn}"
"DB_PASSWORD" = azurerm_postgresql_server.app_database_server.administrator_login_password
}
site_config {
dotnet_framework_version = "v5.0"
}
}(Siehe app.tf)
Auf- und Abbau der Infrastruktur
Grundsätzlich bietet Terraform drei Operationen: Plan, Apply und Destroy. Plan vergleicht den Ist-Zustand mit dem Soll-Zustand, der durch den Terraform-Code definiert ist, und ermöglicht die Darstellung und das Abspeichern der erforderlichen Änderungen. Apply und Destroy führen die berechneten Änderungen tatsächlich aus. Das Erstellen eines Plans ist nicht zwingend nötig und nur in automatisierten Szenarien empfehlenswert, wenn eine Nachverfolgung erforderlich ist. Im Standard-Fall wird der Plan automatisch bei Ausführung einer der beiden anderen Operationen berechnet. Der Plan würde in unserem Fall feststellen, dass noch nicht alle Ressourcen existieren und diese als „muss erstellt werden“ markieren. Terraform führt bestimmte Operationen parallel aus, sollten sie nicht voneinander abhängen. In folgender Grafik ist der Prozess für das erstmalige Erstellen dargestellt.
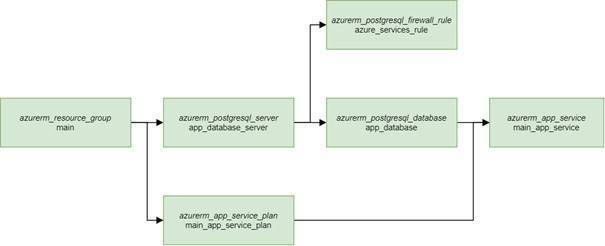
Anschließend kann die Beispielanwendung etwa über die Visual Studio IDE oder eine CI/CD-Pipeline in den App-Service bereitgestellt werden. Wird die Umgebung nicht mehr benötigt, kann sie leicht und schnell mit dem Befehl [terraform destroy] abgebaut werden.
Terraform bietet darüber hinaus noch viele weitere Features und Mechanismen an, die die Arbeit enorm erleichtern. Dazu zählen unter anderem Variablen, Parameter, Ausgabewerte und das State Management. Was besonders hilft, wenn mehrere Teammitglieder am gleichen Terraform-Code arbeiten.
Fazit: Infrastruktur in Cloud-Umgebungen schnell und effizient mit Terraform bearbeiten
Wir haben gesehen wie schnell und effizient die Infrastruktur in Cloud-Umgebungen mit Terraform auf- und abgebaut werden kann. Da es sich bei dem entstandenen Produkt um Code handelt, kann hier bereits vorhandenes Know-how für die Code-Verwaltung (zum Beispiel Git) wiederverwendet werden. Auch kann der Code modularisiert und erneut genutzt werden, wodurch die Effizienz noch einmal steigt.