In einer immer schnelllebigen Zeit geht es auch in der IT mehr und mehr darum flexibler und agiler zu sein. Ein agiles Projektmanagement (z.B. Scrum oder Kanban) schafft hierfür die Grundvoraussetzung, um flexibel auf Kundenwünsche und geänderte Projektumstände zu reagieren. Wie aber lässt sich der entwickelte Code permanent testen und anschließend schnell und automatisch an die Endanwender ausliefern? Hier hört man immer häufiger von CI/CD. Doch was heißt das eigentlich genau und wie funktioniert es in der Praxis?
Dieser Artikel soll eine Brücke zwischen Theorie und Praxis schlagen. Durch meine Erfahrungen aus einem großen Java-Projekt kann ich beurteilen, wie eine optimale Systemumgebung aussehen sollte und welche weiteren Bedingungen erfüllt sein müssen. So werden im Weiteren die folgenden Fragen geklärt: Welche Voraussetzungen werden für CI/CD benötig? Wie baue ich eine CI/CD Pipeline in meinem Projekt auf? Welche Hindernisse und Probleme müssen bewältigt werden, um zum Erfolg zu kommen? Wie wirkt sich die Einbindung von CI/CD in der Praxis auf den Projekterfolg und vor allem auf die Zeitspanne von der Entwicklung bis zum produktiven Einsatz aus? Was für Vorteile bringt der Einsatz langfristig mit sich?
CI/CD – Was genau ist das eigentlich?
Es handelt sich bei CI/CD um Methoden, bei denen sowohl den Kunden und Endanwendern als auch dem Entwicklerteam regelmäßig lauffähige Software bereitgestellt wird und alle Phasen der Anwendungsentwicklung automatisiert ablaufen können.
„CI“ bedeutet hierbei Continuous Integration, also der Automatisierungsprozess für das Entwicklerteam. Bei einer erfolgreichen CI werden durch das Team regelmäßig neue Codeänderungen für die Anwendungen entwickelt, geprüft und in einem gemeinsamen zentralen Repository zusammengeführt.
Bei der modernen Anwendungsentwicklung arbeiten mehrere Entwickler an unterschiedlichen Features der gleichen Anwendung. Ohne den Einsatz von Continuous Integration kann die gleichzeitige Zusammenführung aller Quellcode-Branches an einem Tag (auch bekannt als „Merge Day“) einen hohen Arbeits- und
Zeitaufwand bedeuten. Der Grund dafür ist, dass Anwendungsänderungen von getrennt arbeitenden Entwicklern miteinander in Konflikt treten können, wenn sie zeitgleich durchgeführt werden.
Mithilfe der Continuous Integration können Entwickler ihre Codeänderungen in einem gemeinsamen „Branch“ der Anwendung viel häufiger zusammenführen, sogar mehrmals täglich. Sobald die Änderungen eines Entwicklers zusammengeführt werden, werden sie in automatischen Builds und unterschiedlichen Stufen von Automatisierungsprüfungen (normalerweise Unit- und Integrationstests) validiert. So wird sichergestellt, dass die Funktionsfähigkeit nicht beeinträchtigt wurde. Dabei müssen alle Klassen und Funktionen bis hin zu den verschiedenen Modulen der Anwendung getestet werden. Wenn die automatische Prüfung Konflikte zwischen aktuellem und neuem Code erkennt, lassen sich diese mithilfe von CI schneller und dadurch einfacher beheben.
„CD“ bedeutet Continuous Delivery bzw. Continuous Deployment. Beide Konzepte sind verwandt und werden im Projektgeschäft teilweise synonym verwendet. Obwohl es bei beiden Konzepten um die Automatisierung weiterer Phasen der Pipeline geht, unterscheiden sie sich tatsächlich aber im Ausmaß der Automatisierung.
Continuous Delivery bedeutet üblicherweise, dass Änderungen eines Entwicklers automatisch auf Bugs getestet und in ein zentrales Repository hochgeladen werden, von wo aus sie vom Team händisch in einer Live-Produktionsumgebung verwendet werden können. Dieser Vorgang ist die Antwort auf Transparenz- und Kommunikationsprobleme zwischen Dev- und Business-Teams. Damit soll sichergestellt werden, dass neuer Code mit minimalem Aufwand implementiert werden kann. Ziel der Continuous Delivery ist eine Codebasis, die jederzeit für die Implementierung in einer Produktionsumgebung bereit ist.
Continuous Deployment wiederum automatisiert zusätzlich auch noch die Freigabe von Entwickleränderungen vom Repository zur Produktionsumgebung, wo sie direkt vom Endanwender genutzt werden können. Dieser Vorgang soll der Überlastung von Ops-Teams bei manuellen Prozessen entgegenwirken, die die Anwendungsbereitstellung verlangsamen.
Da hier der Produktionphase in der Pipeline kein manuelles Gate mehr vorgeschaltet ist, müssen beim Continuous Deployment die automatisierten Tests immer sehr gut durchdacht sein.
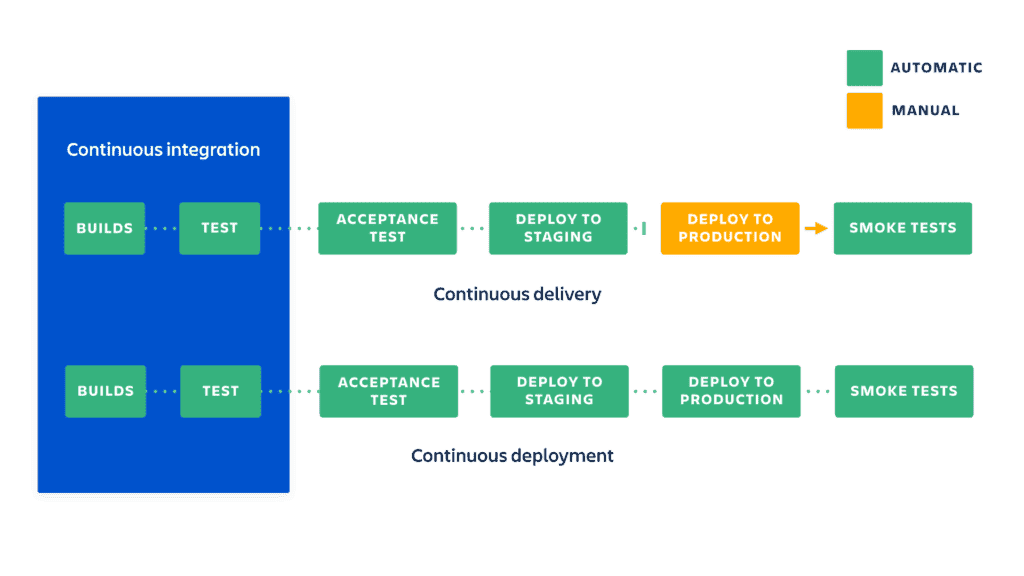
Abbildung 1: Zwei Arten von CI/CD-Pipelines (© https://www.atlassian.com/continuous-delivery/principles/continuous-integration-vs-delivery-vs-deployment)
Wie sieht eine solche Umgebung in der Praxis aus?
Aus meiner persönlichen Praxiserfahrung bei einem großen Kunden habe ich Erfahrungen mit folgenden Systemen machen können:
Git (Bitbucket), Maven, Jenkins, JFrog Artifactory, Oracle Database, Weblogic Server
Grundsätzlich lässt sich sagen, dass agile Methoden der Softwareentwicklung prädestiniert für die Verwendung einer CI/CD-Pipeline sind. Sie haben beide die kurzen Intervalle, permanent lauffähige Software und schnelle Reaktionszeiten als Ziel.
Bei jedem Commit im Git-Repository wird über einen Bitbucket-Hook der entsprechende Jenkins-Build-Job ausgelöst und beginnt nun die neue aktuelle, veränderte Codebasis auszuchecken, den Code mit Maven zu bauen, Tests zu starten und anschließend die gebauten Jar‘s in das zentrale Artifactory zu deployen.
Somit ist es jedem Entwickler sofort möglich die neueste Codebasis zu verwenden und seine eigene Entwicklung kompatibel zu halten. Das Entwicklerteam ist untereinander möglichst stark synchronisiert, dabei arbeiten die einzelnen Entwickler
aber weiterhin so autark wie möglich. Dies ist der Kerngedanke der Continuous Integration.
Ebenso hat jeder Entwickler durch die automatisierten Builds des Jenkins die Möglichkeit, seine Implementierung sehr schnell auf einem Testsystem zu verwenden und Probleme frühestmöglich zu erkennen.
Sollte es im Build-Prozess bereits zu Fehlschlägen bei Tests kommen, erhält der Entwickler automatisch eine E-Mail dazu. Die Jar‘s landen in diesem Fall natürlich auch nicht im Artifactory und behindert somit nicht die Entwicklung des restlichen Teams.
Die „Zusatzstufe“, die komplett gebaute Anwendung direkt auf die Produktion zu deployen, wird aktuell im Projekt meines Kunden nicht verwendet, da ein Großteil der Qualitätssicherung noch aus per Hand durchgeführten Smoketests besteht. Dadurch wird der mögliche Geschwindigkeitsvorteil wiederum ausgebremst und stellt keine optimale Umgebung dar.
Welche Voraussetzungen benötigt ein Projekt dafür?
Um CI/CD effektiv und sicher in seinem Projekt einzusetzen bedarf es einigem Zusatzaufwand. Gerade die Vorabinvestitionen sind beträchtlich, da automatische Tests für die diversen Prüf- und Release-Phasen in der CI/CD-Pipeline geschrieben werden müssen.
Ebenso benötigt man die gesamte Infrastruktur für die Jenkinsinstanzen und Git-Repositories. Gerade bei umfangreichen Projekten benötigt man hier schnell eine große Menge an Rechenkapazität. Ohne eine virtualisierte Umgebung stößt man hier sehr schnell an Grenzen der technischen Machbarkeit.
Auch aus meiner Projekterfahrung kann ich sagen, dass der vor kurzem erfolgte Umstieg in die Cloud das ganze Konzept der CI/CD-Pipeline erst skalierbar gemacht hat.
Ein weiterer unumgänglicher Teil zu einer erfolgreichen Arbeit mit CI/CD besteht in einem Team, das entsprechend geschult und eingestellt ist. Die Entwickler müssen mit agilem Projektmanagement vertraut sein und die eingesetzten Tools sicher beherrschen. Zudem muss ein Bewusstsein für die immense Bedeutung der zu schreibenden Tests geschaffen werden.
Ein umfangreiches, über die Jahre gewachsenes Projekt auf eine CI/CD-Pipeline umzustellen, gestaltet sich hierbei umso schwieriger, da die Anpassungen und Umstellungen im laufenden Projektalltag geschehen müssen.
Wo liegen die Schwierigkeiten von CI/CD?
Wie alle automatisierten Systeme birgt auch CI/CD einige Gefahren. So ist die Pipeline nur so gut und sicher wie ihre Implementierung dies vorgibt. Besteht zum Beispiel ein Fehler in der Testauswertung und Fehlschläge werden nicht korrekt behandelt, besteht die Gefahr, dass der Code ohne weitere Kenntnis über den Fehler in das Artifactory oder sogar auf die Produktionsumgebung gelangt.
Ebenso hängt die Qualität und Fehlerquote in der fertigen Anwendung in hohem Maß von der Quantität und Qualität der Unit-, Integrations- und auch Smoketests ab. Werden zu einem neuen Feature keine ausreichenden Testcases erkannt oder diese nicht richtig implementiert, fallen diese Fehler womöglich erst auf der Produktion auf.
Gerade im Hinblick auf die Qualitätssicherung muss das Team verinnerlichen, dass ein beträchtlicher Teil der Entwicklungszeit für das Definieren und Implementieren ausreichender Testszenarien benötigt wird. Auch im Zuge der Qualitätssicherung der umgesetzten Features muss ein besonderes Augenmerk auf den Tests liegen.
Welche Grenzen gibt es?
Die Vorteile der automatisierten Softwareentwicklung und -auslieferung liegen auf der Hand. Die Geschwindigkeit in der entwickelt, getestet und neue Software ausgeliefert werden kann, gerade in großen, dezentralen Projekten an denen viele Entwickler gleichzeitig arbeiten, ist das schlagende Argument. Die Entwickler, der Kunde und auch der Endanwender profitieren unmittelbar von der schnellen Reaktionszeit.
Meine Erfahrung im Projekt hat aber auch gezeigt, dass die Verlagerung dieser ganzen Schritte an einen zentralen Ort auch einen gegenteiligen Effekt haben kann. Steht der Jenkins oder das Artifactory aus trivialen Gründen wie Wartung oder auch Ausfällen nicht zur Verfügung, kann der einzelne Entwickler einen Großteil der Schritte nicht mehr händisch ausführen.
Wie zuvor bereits erwähnt hängt die Skalierbarkeit der CI/CD-Pipeline in hohem Maße vom Einsatz einer cloudbasierten Lösung ab. Gerade in umfangreichen Projekten, mit vielen Tests und großen Datenmengen stößt man ansonsten schnell an die Grenzen der Hardware. Durch die flexible Zuschaltung bei tatsächlich benötigter Rechenkapazität lässt sich das oft zitierte Bottleneck hier vermeiden. Ganz nebenbei kann man durch Abschaltung nicht benötigter Prozessoren auch noch Kosten sparen.
Danke für den ausführlichen Artikel.
Eine Frage zu dem CI hätte ich da noch: Nutzt ihr Feature Branches um sicherzustellen, dass kein fehlerhafter Code im Hauptbranch landet? Wie sorgt ihr dafür, dass dieser up2date bleibt? Lasst ihr Feature Branches max. wenige Tage alt werden? Oder habt ihr einen automatisierten merge (Hauptbranch -> Feature Branches)?
Danke :)
Vielen Dank für das Interesse an meinem Beitrag.
Mittlerweile verwenden wir in dem Projekt auch Feature-Branches. Die Einführung war eigentlich schon viel früher geplant, wurde aber dann doch erst viel später vollzogen. Es waren einige Anpassungen an den Jenkins-Jobs nötig, welche im laufenden Betrieb vollzogen werden mussten.
Durch die Nutzung von Feature-Branches haben wir nun die deutlich sicherere Variante, um auch größere Refactorings und Features mit Toolunterstützung umzusetzen.
Auch der Merge in den Hauptbranch wurde als Jenkins-Job realisiert. Dieser prüft, ob alle Tests in dem entsprechenden Branch erfolgreich waren und auch SonarQube keine Codesmells gefunden hat.
Das Problem mit veralteten Feature-Branches haben wir bis jetzt nicht automatisiert gelöst. Aktuell kann es vorkommen, dass vor dem Merge in den Hauptbranch noch einmal der Feature-Branch angereichert werden muss. Hier überlegen wir noch, ob ein nächtlicher merge in alle Feature-Branches hilfreicher und mit den momentanen Hardwareressourcen umsetzbar ist.
Bei weiteren Fragen oder detaillierteren Erläuterungen gerne einfach Fragen.