Die Schnittstellentechnologie GraphQL wird von immer mehr Firmen eingesetzt. Die Technologie bringt besondere Eigenschaften mit, die sie von den bewährten Technologien wie REST und SOAP abgrenzt. In diesem Artikel wird näher darauf eingegangen, wie diese Technologie dazu verwendet werden kann, um die bestehenden Schnittstellen gebündelt bereitzustellen.
GraphQL
GraphQL ist eine von Facebook intern für die eigene Plattform entwickelte Schnittstellentechnologie, sowie die zugehörige Abfragesprache. Seit der Open-Source- Veröffentlichung im Jahre 2015 bekommt die Technologie immer mehr Zuspruch und wird bereits von großen Unternehmen wie Twitter, PayPal und Airbnb produktiv eingesetzt. Ende 2018 hat Facebook die GraphQL-Foundation gegründet, bei der neben den bereits genannten Firmen auch Technologieriesen wie Amazon und IBM die Technologie fördern.
GraphQL unterscheidet sich zu den üblichen Schnittstellentechnologien wie SOAP und REST darin, dass keine Endpunkte mit vordefinierten Datenstrukturen verwendet, sondern die Daten ähnlich wie bei SQL explizit abgefragt werden. Daten können außerdem graph-orientiert, also über deren Beziehungen, abgefragt werden. Aus diesen beiden Eigenschaften setzt sich auch der Name „GraphQL“ zusammen (QL steht für Query Language).
Die Hauptvorteile für diesen Ansatz sind, dass Over- und Underfetching vermieden werden können. Bei Restendpunkten wird vordefiniert, welche Daten beziehungsweise. Spalten zurückgegeben werden. Dies führt dazu, dass mehr als eigentlich benötigte Daten transportiert werden (Overfetching). Besonders für Anwendungen, die auch mobil genutzt werden, können daraus spürbare Ladeverzögerungen resultieren. Ein Lösungsansatz für Overfetching ist die Menge an Daten, auf mehrere kleinere Endpunkte aufzuteilen. Was daraus wiederum resultieren kann, ist, dass mehrere Anfragen gesendet werden müssen, um alle benötigten Daten zu erhalten (Underfetching). Mehrere Anfragen zu versenden, ist gegenüber einer einzigen ebenfalls ineffizient. In Folge dessen muss entweder für jeden spezifischen Anwendungsfall ein Endpunkt eingerichtet oder diese Ineffizienz in Kauf genommen werden.
GraphQL löst diese beiden Probleme mit der Abfragesprache, sodass die benötigten Spalten explizit angefordert werden müssen. So erhält der Konsument der Schnittstelle nur die Daten, die er wirklich benötigt. Außerdem lassen sich über die Beziehungen der Entitäten flexibel zusammenhängende Daten abfragen. Falls so immer noch nicht alle Daten abgefragt werden können, kann eine GraphQL-Anfrage mehrere Abfragen enthalten.
Um diese Flexibilität zu ermöglichen, muss in der Schnittstelle ähnlich wie bei einer relationalen Datenbank, ein Schema definiert werden. Schemata bestehen aus den folgenden fünf Bausteinen:
- Types
- Queries
- Mutations
- Subscriptions
- Resolvers
Types definieren Datenstrukturen und deren Datentypen. Außerdem wird angegeben, ob es sich bei einer Spalte um ein Pflichtfeld handelt und ob ein Datensatz oder ein Array aus mehreren zurückgegeben werden muss. Im Gegensatz zu REST überprüft GraphQL auf Datentypen und Pflichtfelder und gibt bei einem Verstoß eine Fehlermeldung zurück. Dies hat den Vorteil, dass so Folgefehler bei der Verarbeitung vermieden werden. Beziehungen können abgebildet werden, indem als Datentyp eine andere GraphQL-Datenstruktur referenziert wird. In Abbildung 1 sind die zwei Typen, Movie und Actor, in der GraphQL-Schema-Definitionssprache dargestellt.

Queries, Mutations und Subscriptions bilden die verfügbaren Operationen ab. Queries sind Abfragen, die dem Konsumenten bereitgestellt werden und somit auch Einstiegspunkte in das Schema. Eine Query muss immer einen Datentypen zurückgeben, über deren Beziehungen dann weitere Datentypen abgefragt werden können. In Abbildung 2 wird über die Query „searchMovie“ mit dem Parameter „Matrix“ für den Titel ein Film zurückgegeben. Über die definierte Beziehung zu Schauspielern können so Informationen zu beispielsweise Keanu Reeves abgefragt werden und über die Beziehung von Schauspielern zu Filmen wiederum weitere Filme, in denen der Schauspieler mitspielt. Dieses Spiel könntebis ins Unendliche getrieben werden.

Mutations sind datenverändernde Operationen. Ähnlich zu Queries kann eine Mutation auch Daten zurückgeben. Über Subscriptions können Konsumenten Ereignisse abonnieren und bekommen Datenänderungen anschließend über Websockets gepusht. Dies ist nützlich für Anwendungsfälle wie Chats, wo die Konsumenten so schnell wie möglich neue Nachrichten erhalten müssen und periodische Abfragen und damit verbunden unnötige Last vermieden werden kann.
Resolver enthalten die Logik, die von GraphQL ausgeführten Operationen zu erfüllen. Diese Resolver müssen eigenständig programmiert werden und somit ist es für den GraphQL-Server völlig irrelevant, woher die Daten kommen oder wohin Daten geschrieben werden. In diesem Beispiel könnte für die Abfrage „searchMovie“ eine simple Datenbankabfrage hinterlegt werden, welche Filminformationen und Schauspieler-IDs zurückgibt. Über einen
Resolver, welcher für Schauspieler-IDs deren Informationen zurückgibt, können dann die Schauspielerdaten gesammelt werden. Die Resolver selbst haben keine Vorgaben, müssen lediglich die erwarteten Daten zurückgeben. So können auch einfach verschiedene Datenquellen für das GraphQL-Schema vermischt werden.
Die offizielle Referenz für GraphQL wurde von Facebook für JavaScript entwickelt. Durch die Community wurden allerdings viele Implementierungen in Sprachen wie Go, C#, Python und Java umgesetzt. Unter folgendem Link ist eine Übersicht der verfügbaren Softwarepakete
aufgelistet: https://graphql.org/code
Serviceorientierte ITLandschaften sind überall
In den meisten IT-Landschaften von Unternehmen befinden sich eine Vielzahl verschiedener
Schnittstellen. Ob Datenbanken, ERP-Systeme oder DevOps-Server, mittlerweile wird fast jedes System mit einem SOAP oder REST-Webservice ausgestattet. Über eine daraus entstehende serviceorientierte Architektur können somit flexibel über ein standardisiertes Protokoll auf fremden Systemen Prozesse gestartet und Informationen angefragt werden. Daraus resultiert, dass die gesamte Systemlandschaft eine hohe Interoperabilität aufweist.
Allerdings bringt so ein „Service-Dschungel“ auch einige Nachteile mit sich. Wenn nun viele Anwendungen und Systeme über diese Schnittstellen mit anderen Systemen kommunizieren, entstehen viele Punkt-zu-Punkt-Verbindungen. Dies hat zur Folge, dass ein großes Netz aus Abhängigkeiten über die Webservices entstehen. Meistens sind die Systeme sehr stark gekoppelt, was zur Folge hat, dass viele Anwendungen nicht mehr korrekt funktionieren, wenn eine wichtige Schnittstelle ausfällt. Wartungen oder Updates können somit ein großes Risiko für die Konsumenten darstellen.
Ein weiterer Faktor ist, dass oftmals in Unternehmen relativ intransparent ist, welche Schnittstellen überhaupt existieren, wie diese genau funktionieren und wer diese
konsumiert. Letzterer Punkt kann zum Beispiel dazu führen, dass die Abschaltung alter
Systeme unvorhergesehene Folgen mit sich bringt. Meistens werden Webservices nicht zentral aufgelistet und dokumentiert, sodass Entwickler nicht von der Existenz einiger Services wissen. Dies ist problematisch, wenn deswegen bereits vorhandene Logik doppelt programmiert wird.
GraphQL als Middleware zur Bündelung von Schnittstellen
Um den im vorherigen Kapitel genannten Problemen entgegenzuwirken, könnte GraphQL dazu eingesetzt werden, Webservices im Unternehmen in einer zentralen Middleware zu bündeln und darüber bereitzustellen. Wie eine solche Systemlandschaft aussehen könnte, ist in Abbildung 3 dargestellt.
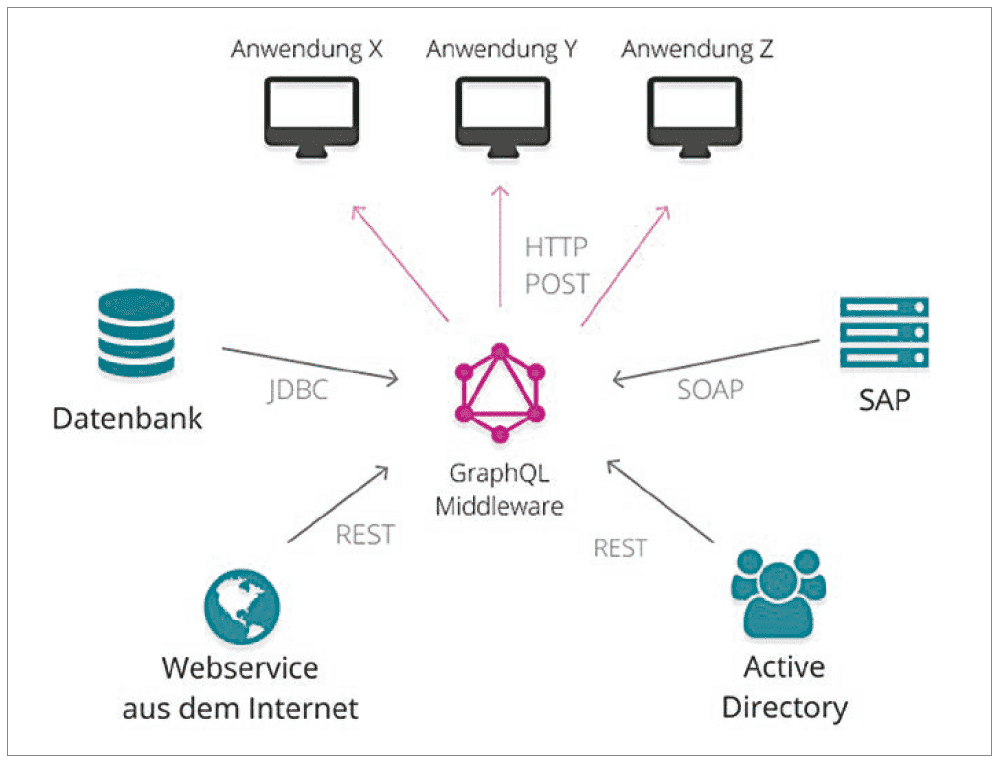
Der Vorteil einer zentralen Middleware, welche Schnittstellen bündelt, ist, dass alle Konsumenten im Optimalfall nur noch die eine Abhängigkeit zur Middleware haben. Somit muss nur noch sichergestellt werden, dass die Konsumenten im Rahmen ihrer Berichtigungen auf diese Middleware zugreifen können und nicht auf die hinterlegenden Systeme. Die Konsumenten müssen außerdem nur noch eine Schnittstellentechnologie implementieren. So eine Implementierung bringt meistens einen kleinen Overhead mit sich, wenn etwa XML-Anfragen für SOAP-Requests zusammengebaut werden müssen.
Für die Entwickler ist zu jeder Zeit ersichtlich, welche Daten und Operationen verfügbar sind. Die hinterlegenden Systeme und die Logik zu deren Anbindung an die Middleware ist wie eine Blackbox vollkommen nach außen abgekapselt, was die Komplexität runterbricht. Die Entwickler können sich folglich rein auf den Konsum der Middleware-Schnittstelle konzentrieren, und nicht darauf was technisch dahinter liegt.
An dieser zentralen Stelle können dann auch Logging- und Monitoring-Funktionalitäten implementiert werden, um einen Überblick zu erhalten, welche Daten wann, wie häufig von wem verwendet werden. Auch Caching und Authentifizierung sowie Autorisierung kann an dieser zentralen Stelle umgesetzt werden. Kleine Datenverarbeitungen können gezielt in der Middleware platziert werden, damit die Konsumenten die Daten so wenig wie möglich selbst weiterverarbeiten müssen. Diese Logiken sind dann wiederverwendbar und verhindern somit, dass Abläufe für verschiedene Konsumenten doppelt programmiert werden.
Ein weiterer Vorteil ist, dass in der Middleware Fehlerroutinen implementiert werden können. Wenn zum Beispiel ein System ausfällt, aber ein zweites System mit ähnlichen Daten vorhanden ist, könnten die Abfragen auf dieses System umgeleitet werden und so Störungen global für alle Konsumenten vermieden werden.
Diese Vorteile sind beispielsweise auch mit Enterprise-Service-Bussen erzielbar. GraphQL bietet für einen solchen Ansatz zusätzliche Vorteile. Dadurch, dass bei GraphQL gezielte Abfragen getätigt werden, können Entwickler deutlich flexibler die benötigten Informationen abrufen. Es muss keine hohe Anzahl an Endpunkten definiert werden, welche auf die Konsumenten zugeschnitten sind. Daten aus verschiedenen Quellen können gebündelt unter einem GraphQL-Type angeboten werden. Da durch den graph-orientierten Ansatz der Technologie zusammenhängende Daten über deren Beziehung abgefragt werden, kann so flexibel durch das Schema navigiert werden. Da in der Middleware das Schema sehr groß werden sollte, verschaffen die Beziehungen einen Überblick über die Datenzusammenhänge.
GraphQL ist zusätzlich quasi selbstdokumentierend. Da ein Schema strikt definiert werden muss, wird diese programmierte Struktur verwendet, um Informationen über die verfügbaren Abfragen, Operationen und Datentypen nach außen freizugeben. In der Regel stellt ein GraphQL-Server auch eine Weboberfläche bereit, in der diese generierte Dokumentation einsehbar ist und wo Abfragen und Operationen auch getestet werden können.
Allerdings sollte auch beachtet werden, dass eine GraphQL-Schnittstelle deutlich aufwendiger zu programmieren und wartungsbedürftiger ist, als beispielsweise eine REST-Schnittstelle. Die erzielte Flexibilität kann also dazu führen, dass die Schnittstelle unperformant wird und auf Grund dessen aufwendige Optimierungen vorgenommen werden müssen.